Úvod
Normalizácia databázy je
dôležitý krok pri návrhu, vývoji, a
implementovania nového informačného systému, ako aj spätnej analýzy existujúeho
návrhu informačného systému. Najväčšia výhoda normalizácie
je odstránenie dátovej redundancie (t.j.opakovaný výskyt tých istých dát v
systéme) a zaistenie správnosti vzťahov medzi dátami - integrity
dát. Správna
konfigurácia normalizovaných
tabuliek súčasne s dobrým výberom indexácie tabuliek (t.j. vhodne riešeným
systémom prístupových klúčov) vedú k vyším výkonom aplikácie a
jednoduchšej správe databázovej aplikácie.
Proces normalizácie predstavuje sled 4 normalizačných krokov, z ktorých každá
vedie k vyššiemu stupňu normalizácie. Ich poradie je dôležité, nedajú sa
obísť resp. preskočiť. Ich úlohou je usporiadať dátové položky do vhodných
skupín a vytvoriť medzi skupinami správne vzťahy. Sú to tieto: prvá,
druhá, tretia a Boyce-Codd
-ová Normálna forma, označované aj 1NF
→ 2NF
→ 3NF
→ BCNF
.
Po pochopení koncepcie normalizácie, ukážeme si ako
zvoliť indexy pre tieto tabuľky (index = prístupový kĺúč).
Prvá Normálna Forma
Predpokladajme že máme sytém evidencie študentov, ktorý predstavuje takáto
tabuľka:
| ID študenta |
Priezvysko |
Meno |
Špecializácia |
Dátum narodenia |
Kurz |
Inštruktor kurzu |
| 123 |
Smith |
Joe |
Computer Engineering |
1/1/1980 |
CSE 441W |
Raj |
| 123 |
Smith |
Joe |
Computer Engineering |
1/1/1980 |
CSE 471 |
Das |
| 123 |
Smith |
Joe |
Electrical Engineering |
1/1/1980 |
EE 310 |
Choi |
| 234 |
Doe |
Jane |
Business |
2/4/1981 |
MGMT 100 |
Clark |
| 234 |
Doe |
Jane |
Business |
2/4/1981 |
MIS 442 |
DeMartino |
| 678 |
Brasky |
Bill |
Computer Science |
1/9/1982 |
MIS 442 |
DeMartino |
| 678 |
Brasky |
Bill |
Computer Science |
1/9/1982 |
CSE 471 |
Das |
Čo má definované tabuľka v
Prvej Normálnej forme (1NF)?
-
Všetky možné kľúčové atribúty sú definované. - To znamená, že
všetky atribúty, ktoré môžu jednoznačne identifikovať riadok už sú
definované.
-
V tabuľke sa nenachádzajú opakujúce sa skupiny dát. - Je nevyhnutné
odstrániť redundantné dáta a zaistiť the accuracy of the data fundamental to
relational databases.
-
Všetky atribúty sú závislé od primárneho kľúča. - Je daný jedinečný
primárny kľúč, všetky ostatné hodnoty súod neho závislé. Primárny kľúč
identifikuje jeden a iba jeden riadok.
Ako transformovať tabuľku do prvej normálnej formy.
-
Opakujúce sa skupiny musia byť odstranené - Odstránime všetky opakujúce
sa hodnoty (ID študenta, Priezvysko, Meno, Špecializácia, Dátum
narodenia) a dostanete nasledovnú tabuľku.
-
Správny primárny kľúč navrhnutý tak, aby jednoznačne identifikoval
riadky. - Navrhneme zložený primárny kúč pozostávajúci z viacerích
datových položiek (ID študenta, Špecializácia, Kurz) nakoľko iba
kombinácia týchto troch hodnôt jednoznačne identifikuje riadok v danej
tabuľke.
Tu je nanovo definovaná tabulka v 1NF:
| ID študenta |
Priezvysko |
Meno |
Špecializácia |
Dátum narodenia |
Kurz |
Inštruktor kurzu |
| 123 |
Smith |
Joe |
Computer Engineering |
1/1/1980 |
CSE 441W |
Raj |
| |
|
|
|
|
CSE 471 |
Das |
| |
|
|
Electrical Engineering |
|
EE 310 |
Choi |
| 234 |
Doe |
Jane |
Business |
2/4/1981 |
MGMT 100 |
Clark |
| |
|
|
|
|
MIS 442 |
DeMartino |
| 678 |
Brasky |
Bill |
Computer Science |
1/9/1982 |
MIS 442 |
DeMartino |
| |
|
|
|
|
CSE 471 |
Das |
Druhá Normálna Forma
Čo má definované tabuľka v
druhej normálnej forme (2NF)?
-
Má všetky vlastnosti tabuľky v 1NF.
-
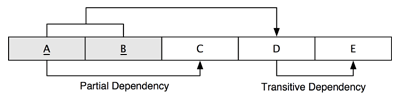
Nezahŕňa žiadne čiastkové závislosti -
každý atribút v
tabuľke závisí od celého primárneho kľúča a nie od časti zloženého
kúča. V nasledovnom príklade je položka C závislá na časti primárneho
kľúča A, takže ide o čiastkovú závislosť C.
Ako transformovať tabuľku do druhej normálnej formy.
-
Začnete s tabuľkou vo formáte 1NF
-
Rozčleníme originálnu tabuľku do viacerích tabuliek tak, že primárne
kľúče týchto nových tabuliek budú atribútmi z pôvodnej tabuľky.
Napríklad, potrebovali by sme vytvoriť nové tabuľky závislé od
nasledovných primárnych kľúčov:
ID študenta
Kurz
ID študenta, Špecializácia
ID Študenta, Kurz
-
Klúče sme vybrali tak, aby jednoznačne identifikovali všetky položky
v novej tabuľke tak, že tieto budú závislé od celého primárneho kľúča
a jedine od primárneho klúča a žiadnej jeho časti. [ID študenta, Špecializácia]
určuje akú špecializáciu študent má, ale zároveň umožňuje, aby študent
mal viacero špecializácií. Ten istý princíp využíva kombinácia [ID
študenta, Kurz], kde každý študent môže byť zapísaný do viacerích
kurzov. Teraz máme nasledovné 4 tabuľky:
[ID študenta, Priezvysko,Meno,
Dátum narodenia]
[Kurz, Inštruktor kurzu]
[ID študenta, Špecializácia]
[ID študenta, Kurz]
Tabuľka študenta
| ID študenta |
Priezvysko |
Meno |
Dátum narodenia |
| 123 |
Smith |
Joe |
1/1/1980 |
| 234 |
Doe |
Jane |
2/4/1981 |
| 678 |
Brasky |
Bill |
1/9/1982 |
Tabuľa kurzov
| Kurz |
Inštruktor kurzu |
| CSE 441W |
Raj |
| CSE 471 |
Das |
| EE 310 |
Choi |
| MGMT 100 |
Clark |
| MIS 442 |
DeMartino |
Tabuľa špecializácie študenta
| ID študenta |
Špecializácia |
| 123 |
Computer Engineering |
| 123 |
Electrical Engineering |
| 234 |
Business |
| 678 |
Computer Science |
Tabuľka kurzov študenta
| ID študenta |
Kurz |
| 123 |
CSE 441W |
| 123 |
CSE 471 |
| 123 |
EE 310 |
| 234 |
MGMT 100 |
| 234 |
MIS 442 |
| 678 |
MIS 442 |
| 678 |
CSE 471 |
Tretia Normálna Forma
Čo definuje tabuľka v tretej normálnej forme?
-
Podmienka je, že tabuľka je už v 2NF
.
-
Neobsahuje žiadne tranzitívne závislosti. -
V tabuľke už nie sú žiadne
atribúty, ktoré by záviseli od nejakého iného atribútu, ktorý
nie je súčasťou Primárného kľúča.
Inak povedané: Všetky nekľúčové atribúty sú
navzájom nezávislé. V
nasledovnom príklade atribút E závisí od D, takže E je tranzitívne
závislý od D.
Ako transformovať tabuľku do tretej normálnej formy.
-
Vytvorte separovanú(-né) tabuľku(-ky) aby ste odstránili tranzitívnu
závislosť. Primárnym klúčom novej tabuľky je atribút od ktorého
tranzitívna závislosť závisela. Tabuľka obsahuje všetky tie atribúty
ktoré nový kúč určuje (determinuje)
V našom príklade nemáme žiadne tranzitívne závislosti, ale ak by
kurz nebol časťou primárneho kľúča originálnej tabulky, Inštruktor
kurzu by bol tranzitívne závislý od Kurzu. Nakoľko naše tabuľky nemajú
žiadnu tranzitívnu závislosť, všetky sú už v 3NF.
Boyce-Codd Normálna Forma
Čo definuje tabuľka v Boyce-Codd normálnej forme?
Ako transformovať tabuľku do Boyce-Codd normálnej formy.
Nasledovný príklad nám ukáže ako transformujeme tabuľku do BCNF.
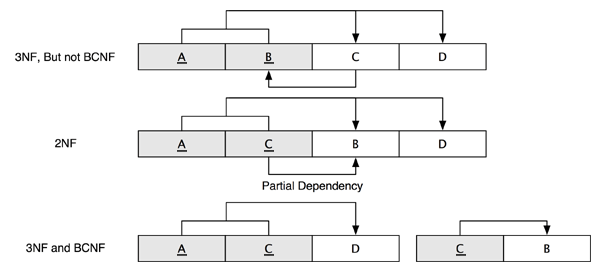
- Najprv môžete vidieť že tabuľka je v 3NF s primárnym kľúčom (A, B)
ktorá určuje C a D; aj keď, nie je v BCNF pretože C určuje B.
- Aby sme to korigovali, môžeme vymeniť B a C tak, že nový primárny kľúč
je (A,
C) a tento determinuje B, D. Toto nás vráti do 2NF pretože C samostatne môže
určovať B.
-
Teraz rozdelíme tabuľku na dve samostatné tabuľky, jednu s primárnym
kľúčom (A,
C) určujúcim D, a druhou s primárnym kľúčom C ktorý určuje B. Tieto
dve nové tabuľky sú v 3NF a BCNF.
Urobte tento rýchly test aby sme videli ako dobre ste doposial
pochopili koncepciu normálnych foriem. Ak budete neuspešný v ľubovolnej otázke,
vrátte sa a pozrite si odskek tak aby ste pochopili svoju chybu.
Indexy
Indexy zvyšujú výkon prehľadávania tabuliek a spájania tabuliek medzi
sebou. Na druhej strane dokážu zároveň spomaliť čas vkladania, mazania a
modifikácie záznamov v tabuľke, preto je veľmi dôležité vybrať vhodné
indexy.
Index je v podstate rýchlejšia cesta ako nájsť riadok s udanou skupinou
informačných položiek. To je to, čo urýchľuje vyhľadávanie vo vnútri
klauzuly WHERE vo vyhľadávacom príkaze. Aby index pracoval efektívne, musí
byť obnovený zakaždým keď je záznam pridaný, zmazaný, alebo modifikovaný.
Databázový server može sa zahltit take a hit ak príliš veľa prebytočných
stĺpcov je indexovaných.
Je tu zopár určitých stlpcov, ktoré by mali byť indexované. Sú to
tieto:
- Primárne Kľúče - Všetky stĺpce,
ktoré sú súčasťou primárneho kľúča mali by byť Indexované. All columns that are part of the primary key should be
indexed.
- Cudzie kľúče - Všetky stĺpce ktoré
referujú na primárne kľúče iných tabuliek mali by byť indexované aby
urýchlili spájanie sa tabuliek. All columns that refer to primary keys of another
table should be indexed to speed joining of tables.
- Stĺpce ktoré sa používajú v častiach WHERE (klauzula KDE v príkazoch
SELECT) veľmi často, ktoré majú početné hodnoty - Indexovanie údaja v
poli PSČ v adrese má význam, ak často potrebujete vyhľadávať ľudí
v danom meste.
- Stĺpce ktoré sa používajú v časti ORDER BY (klauzula PODĽA PORADIA
v príkazoch SELECT) urýchlia zotrieďovanie - Indexovanie podľa poľa
PRIEZVYSKO v adresári urýchli výpis zoznamu podľa PRIEZVYSK.
Je tu zopár stĺpcov ktoré by sa nemali indexovať.
Sú to tieto:
- Stĺpce ktoré majú len veľmi málo možných hodnôt - Indexovanie štúdijného
ročníka študenta nemusí byť efektívne, pretože rozsah hodnôt môže
byť v intervale (1-4) a selektované skupiny majú veľký obsah, spomalia
systém pri modifikácii.
My sme normalizovali originálny spredsheet do nasledovnej skupiny šiestich
tabuliek, použitím štyroch foriem normalizácie, a výberu vhodných kľúčov
a idndexov.
Primárny kľúč by mal byť statický, málokedy sa meniaci. Z toho dôvodu,
sme vytvorili v tabuľke Kurzov číselné pole ID_Kurzy obsahujúce ľubovolné
čísla. Túto stratégiu by sme mohli uplatniť aj v tabuľke Špecializácia,
nahradiac ID_Špecializácie údajmi obsahujúce ľubovolné identifikačné čísla
a tak mať Kód_Špecializácie a Popis_Špecializácie, ktoré budú závisieť
od čísla ID_Špecializácie. To isté by sme mohli urobiť s tabuľkou
Oddelenie. Doporučené indexy pre každú tabuľku by mohli byť takéto:
- Tabulka študentov - (ID_Študenta)- primárny kľúč, (Priezvysko) -
sekundárny kľúč
- Tabulka Špecializácie študenta - (ID_Študenta, ID_Špecializácie) -
primárny kľúč
- Tabuľka špecializácií - (ID_Špecializácie) - primárny kľúč
- Tabuľka študentových kurzov - (ID_Študenta, ID_Kurzu) - primárny kľúč
- Tabuľka kurzov - (ID_Kurzu) - primárny kľúč, (ID_Oddelenia) - sekundárny
kľúč
- Tabuľka oddelení - (ID_Oddelenia) - primárny kľúč
Tabuľka študentov
| ID_Študenta |
Priezvysko |
Meno |
Datum_narodenia |
| 123 |
Smith |
Joe |
1/1/1980 |
| 234 |
Doe |
Jane |
2/4/1981 |
| 678 |
Brasky |
Bill |
1/9/1982 |
Tabuľka špecializácie študenta
| ID_Študenta |
ID_Špecializácie |
| 123 |
CE |
| 123 |
EE |
| 234 |
BUS |
| 678 |
CS |
Tabuľka špecializácií
| ID_Špecializácie |
Popis_Špecializácie |
| CE |
Computer Engineering |
| EE |
Electrical Engineering |
| BUS |
Business |
| CS |
Computer Science |
Tabuľka kurzov študenta
| ID_Študenta |
ID_Kurzu |
| 123 |
321465 |
| 123 |
231654 |
| 123 |
123754 |
| 234 |
367454 |
| 234 |
357495 |
| 678 |
357495 |
| 678 |
321465 |
Tabuľka kurzov
| ID_Kurzu |
Rok |
Semester |
ID_Oddelenia |
Číslo_Kurzu |
Inštruktor |
| 123754 |
2003 |
Fall |
EE |
310 |
Choi |
| 231654 |
2003 |
Fall |
CSE |
441W |
Raj |
| 321465 |
2004 |
Spring |
CSE |
471 |
Das |
| 357495 |
2004 |
Spring |
MIS |
442 |
DeMartino |
| 367454 |
2003 |
Fall |
MGMT |
100 |
Clark |
Tabuľka oddelení
| ID_Oddelenia |
Popis_Oddelenia |
| CSE |
Computer Science and Engineering |
| EE |
Electrical Engineering |
| MGMT |
Management |
| MIS |
Managent Information Systems |