Ako je všeobecne známe, nič na tomto svete nie je osamotené a všetko má nejaké väzby na svoje okolie na ktoré svojim spôsobom vplýva. Pri tvorbe databázy sa zaujímame o Objektívnu realitu (t.j. veci a javy reálneho sveta existujúce okolo nás mimo naše vedomie) okolo nás a snažíme sa ju modelovať formou dát a vzťahov medzi dátami, t.j. vytvárame datové štruktúry. Najpoužívanejšie databázové systémy - relačné databázové systémy - využívajú formu práce a ukladanie dát do tabuliek.
Čo sú to databázy a databázové systémy?
Databázový systém
(resp. systém riadenia bázy dát) je programové vybavenie, čiže
súbor programov, ktoré umožňujú používateľovi vytvárať databázy,
ako aj manipulovať s údajmi
v nich uloženými.
Databázové systémy majú vlastný jazyk v ktorom definujú premenné
pre dáta - určia ich názov, typ a
obor prípustných hodnôt. Majú nástroje
ako takto vytvorené datové položky spájať do skupín identifikovaných
jedným identifikačným kľúčom (entity).
Viac takýchto skupín prepájajú medzi sebou a vytvárajú sieťové štruktúry
vzťahov dát v databáze.
Hlavnou činnosťou databázových systémov je organizovať dátové štruktúry, vytvárať nové dáta, ukladať ich do bázy dát, modifikovať tieto dáta a rušiť nepotrebné dáta. Pracovné metódy a operácie ktoré pri tom používa sú: výber dát z databázy na základe fitrov s definovanými kritériami, zoskupovanie, triedenie, vytváranie medzisúčtov, generovanie výstupných zostáv, prehľadových tabuliek a grafov.
Jednou z najdôležitejších činností je kontrola bezchybnosti dát a štruktúr databázy - integrita dát.
Databáza (resp. báza dát) je súbor(y) navzájom súvisiacich údajov (dát) . Tieto údaje môžu byť:
-
napísané na papieri, kartotékových lístkoch. (napr. kartotéka kníh v knižnici, adresár priateľov, kartotéka CD, telefónny zoznam)
-
uložené v počítači vo forme súborov s dátami.
Databáza je súbor údajov, ktoré sú usporiadané tak, aby podporili vykonávanie špecifických požiadaviek, ako sú vyhľadávanie, triedenie a vzájomná kombinácia údajov.
Podľa spôsobu usporiadania údajov v databázach delíme databázy na:
- sieťové
- hierarchicky usporiadané
- relačné
- objektovo orientované.
Relačné databázy sa vyvinuli ako reakcia na nedostatky skôr používaných
hierarchických a sieťových databáz.
Relačná databáza sa vyznačuje tým, že údaje sú uložené
v tabuľkách. Nie sú
usporiadané do jednej tabuľky, pretože by bola neprehľadná, dlhá a obsahovala by
nadbytočné, opakujúce sa údaje. Údaje máme rozdelené do niekoľkých tabuliek, ktoré
sú navzájom poprepájané pomocou určitých vzťahov, relácií.
Rozdiel medzi informáciami a údajmi.
V bežnom jazyku označujeme týmito slovami to isté: fakty, ktoré získavame,
vyhľadávame. V databázových systémoch týmto slovám prisudzujeme odlišný význam.
Pod slovom Údaj rozumieme číslo, slovo alebo iný symbol, ktorý je uložený v databáze
(napr. 100, Kováč, 1985). Údajom sa tiež hovorí dáta. Samotný údaj nič neznamená, nič
nevysvetľuje.
Informácie sú zmysluplné interpretácie údajov a vznikajú vzájomným prepojením
údajov.( Informáciou nazveme napr. tabuľku zobrazujúcu osobné údaje zamestnancov, riadok
v tabuľke informujúci o zamestnancovi). Pritom pojem zmysluplnosti sa väčšinou vzťahuje
k určitej vymedzenej oblasti, ktorej sa databázový systém týka. Napr. údaje vytvorené ako
záznam priebehu fyzikálneho experimentu (20, 50, 80) môžu pre špecialistu predstavovať
cenné informácie, ale pre nezainteresovaného sú iba číselnými a znakovými reťazcami. Pre
nás sa stávajú zrozumiteľnými až vtedy, keď sa zmysluplne interpretujú (rýchlosť v čase t1 =
20 km/h, rýchlosť v čase t2 = 50 km/h, rýchlosť v čase t3 = 80 km/h).
Informáciami sú dáta, ktoré sú nositeľmi významu pre ľudí.
Informácia je teda produkt,
výstup spracovania dát.
Projektovanie databázových aplikácií.
Samotné programovanie aplikácií musí predchádzať etapa projektu ktorá, keď sa urobí správne, môže samotné programovanie veľmi zjednodušiť. Ide o také veci ako analýza, kreslenie schém systému, písanie dokumentácie, systematické testovanie softvéru (QA - quality assurance) a celkové záležitosti ktoré by sme mohli zahrnúť pod pojem project management. Tento dokument je zameraný na pomoc tohto druhu, ako efektívne postupovať v práci s SQL.
Začnime tým najdôležitejším. Každý tvorca databázy by si mal na začiatku odpovedať na otázku, akú dôležitosť v svojej aplikácii prikladá databáze. Bude databáza základným stavebným kameňom, alebo bude len vedľajším produktom, alebo bude databáza slúžiť ako vedľajší datový sklad? Zvlášť u niektorých jednoduchých aplikácií je dobré sa zamyslieť nad tým, aký úžitok nám prinesie využívanie relačných databáz a či sú relácie potrebné. Občas môže aj trocha šikovnejší súbor poslúžiť lepšie na tie úlohy, na ktoré by niekto chcel nasadiť databázový server. Pre úplnosť spomeňme, že okrem relačného modelu databázy existujú ešte:
- hierarchický model, ktorý je vyjadrený väzbou rodič-potomok a výsledkom je stromová štruktúra. Výhodou takéhoto modelu je rýchlosť, nevýhodou obmedzenie na vyššie spomenutú väzbu. / LDAP/.
- sieťový model je podobný predošlému ale umožňuje, aby záznam mal viac ako jednoho rodiča.
Zopakujme si teda
Základné pojmy o relačných DB
, ktoré budeme potrebovať. Základom relačných databáz sú dvojrozmerné tabuľky, ktoré nazývame entity. Tabuľka sa skladá z riadkov a stĺpcov. Stĺpce nazývame atribúty a riadky jednoducho riadky (rows), alebo n-tice resp. výskyt. Priesečníkom riadka a stĺpca je pole (field). Keď to zhrnieme, každá entita má jeden a viac atribútov a riadkov. Avšak tabuľka len s jedným stĺpcom nemá zmysel.
Budeme sa zaberať prípadom, keď celá aplikácia je postavená na databáze a na narábaní s dátami (ukládanie a modifikácia,...). V tomto prípade by mala byť datový model riešený ako samostatná jednotka ktorá sama bude organizovať konzistenciu svojich dát a integritu - t.j. vzťahy medzi dátami.
Povedzme si viac o integrite. Rozlišujeme doménovú, entirovú a referenčnú integritu dát.
Doménovou integritou rozumieme, že na úrovni stĺpcov definujeme obmedzenie na určitý datový typ, prípadne obmedzenie na rozsah hodnôt. V databázovom slangu by sme mohli povedať doména atribútu. Viac o tom vypovedajú príkazy v SQL jazyku napr. CHECK(...) v definícii stĺpcov. Inak povedané doménovú integritu zabezpečuje samotná databáza kontrolou zapisovanej hodnoty.
Entitná integrita je záležitosťou jedznoznačnej identifikácie riadka v rámci tabuľky. Stĺpec, ktorý obsahuje tento identifikátor sa nazýva Primárny kľúč (PRIMARY KEY).
Referenčná integrita (RI) je už medzitabuľkovou záležitosťou. Definuje vzťah dvoch tabuliek, a to pomocou cudzích kľúčov (FOREIGN KEY).
Teraz sa pozrime na otázku modelovania databázy.
Ako už bolo povedané základným stavebným prvkom relačnej databázy je tabuľka. Meno atribútu, ale aj meno tabuľky, by malo byť v jednotnom čísle. Meno tabuľky by malo určovať podstatné meno. Druhá dôležitá vec je, že dikritika môže spôsobovať problémy, preto treba zabudnúť na pravidlá slovenského pravopisu a nepoužívať ich. Programy poskytované v rámci licencie OpenSource (poskytujú aplikacie zadarmo) často nepočítajú s národnými úpravami.
Pri návrhu tabuľky sa snažíme o tzv. NORMALIZÁCIU. Normalizácia je postup, ktorý vytvára správne skupiny súvisiacich datových položiek a uľahčuje vytváranie vzťahov medzi skupinami. Normalizované štruktúry sa dajú efektívne udržiavať. Normalizácia má niekoľko etáp, a žiadnu nesmieme preskočiť. Cieľom je dosiahnúť čo najvyšší stupeň.
Predtým ako začneme upravovať niečo, to niečo musíme vytvoriť. Preto pri prvej analýze na jeden papier začneme písať všetky názvy položiek - t.j. údajových polí, ktoré si myslíme že by naša databázová aplikácia mala obsahovať. Potom začneme analyzovať vzťahy medzi položkami a navrhovať prvé tabuľky. Na tieto potom aplikujeme NORMALIZÁCIU t.j. 1NF, 2NF, 3NF (4NF, 5NF).
1.
normálna forma (1NF)
Relácia (tabuľka) je v
prvej normálnej forme pokiaľ každý jej atribút (stĺpec) obsahuje len
atomické hodnoty, t.j. hodnoty, ktoré z pohľadu databázy sa už ďalej
nedajú deliť na menšie. Táto podmienka napríklad nie je splnená ak napríklad
máme meno a priezvisko v jednom stĺpci a pritom aplikácia pracuje s týmito
položkami ako samostatnými.
2.
normálna forma (2NF)
Relácia sa nachádza v
druhej normálnej forme, pokiaľ spĺňa podmienky 1NF a
každý nekľúčový
atribut je plne závislý od primárneho klúča, a to od celeho kľúča a
nie od hociakej jeho podmnožiny v prípade zloženého
primárneho kľúča.
3. normalni forma (3NF)
V
tejto forme sa nachádza tabuľka ak spĺňa podmienky 1NF a 2NF a všetky jej
neklúčové atribúty sú vzájomne nezávislé. Napríklad ak množina
obsahuje Jednotkovú cenu a Množstvo, potom by nemala obsahovať
Cenu celkom
ktorá sa vypočíta na základe rovnice vloženej do databázy:
CenaCelkom = JednotkováCena * Množstvo.
Tabuľka by mala mať aspoň dva atribúty. Pri väčšom množstve atribútov je naopak výhodné ju preskúmať či nejaká časť by sa nedala vyčleniť ako samostatná tabuľka. V prípade, že sa rozhodujeme, či vyčleniť nejaké atribúty do osobitnej tabuľky a či nie, urobíme tak vtedy, ak nájdeme aspoň dva také atribúty, ktoré môžu spolu založiť tabuľku.
Tu treba spomenúť že existujú dátové modely, ktoré sa zámerne vytvárajú tak, že nie úplne vyhovujú podmienkam normalizácie tabuliek. Zvyčajne ide o oblasť datových skladov (data warehouse - DW) a tzv. multidimenzionálne databázy (ak vôbec v takomto prípade sa použijú relácie, keď lepšie vyhovujú objektové prístupy). Ale táto oblasť je nad rámec tohto článku.
Vyššie spomenuté pravidlá pre Normálne formy sú veľmi užitočné pri návrhu štruktúry databáz. Uživateľ ušetrí veľa problémov pri návrhu databázy. Zvyčajne začiatočníci majú snahu celú aplikáciu vtlačiť do jedinej resp. do mála tabuliek a tak sa pripravia o základné vlastnosti ktoré im kvalitný SQL server môže poskytnúť. Správny návrh databázy umožňuje dávať odpovede na veľké množstvo variacií otázok.
Teraz keď už sme schopní vytvoriť tabuľku môžeme pristúpiť k pospojovaniu tabuliek do jednoho celku. Dve tabuľky sú spojené vždy tak, že jedna poskytuje primárny kľúč a druhá tabuľka vytvára na ňu referenciu, t.j. odvoláva sa na ňu cez názov a hodnoty kľúčovej položky, t.j. stĺpec (resp. stĺpce), ktoré obsahujú hodnoty primárneho kľúča prvej tabuľky. Túto referenciu nazývame Cudzí kľúč. Nemusí ísť nutne o dve rôzne tabuľky, ale môže ísť aj o jednu tabuľku v ktorej budeme definovať vzťahy medzi záznamami (napríklad hierarchiu otec - syn, predchodca - nasledovnik, ...). Taktiež primárny a Cudzí kľúč nemusí byť nutne tvorený jediným stĺpcom, ale aj viacerími stlpcami naraz, napríklad:
CREATE TABLE prim
(
id int,
num int,
data text,
PRIMARY KEY(id, num)
);
CREATE TABLE fk
(
id serial PRIMARY KEY,
p_id int,
p_num int,
name vharchar(10),
FOREIGN KEY(p_id, p_num) REFERENCES prim(id, num)
);
CREATE TABLE hier
(
id serial PRIMARY KEY,
parent int REFERENCES hier (id),
name varchar(32)
);
Vzťahy (relationship) medzi tabuľkami sú:
Väzba one-to-one (1:1)
Vyjadruje
vzťah, keď práve jeden záznam má vzťah k práve jednomu jedinému inému
unikátnemu záznamu. Napríklad každy jeden unikátny občan SR má jedno
unikátne rodné číslo. Táto väzba nie je často využívaná pretože sa väčšinou
dáta s takouto väzbou umiestnujú v rámci jednej tabuľky.
Väzba one-to-many (1:N)
Ide
o najčastejšie používanú väzbu. Atribút v tabuľke môže v tomto prípade
nadobúdať práve jednu hodnotu z množiny hodnôt definovaných v tabuľke
druhej. Napríklad väzmime vzťah človeka a jeho rodného mesta. Miest je
veľa, ale každy z nás sa narodil iba v jednom z nich. Rovnakú väzbu, ale
opačne plní väzba veľa na jednoho many-to-one (N:1).
Vazba many-to-many (M:N)
Peknym
príkladem tejto väzby je vzťah čitateľov a novín. Každé noviny majú veľa
čiteteľov a každý z nich môže byť súčasne čitateľom niekoľkých rôzných
novín. V praxi nejde v SQL tento vzťah vyjadriť
priamo a používa se preto "mezi-tabulka" s väzbami 1:N na požadované tabuľky.
Napríklad pre tabuľku noviny a čitateľ vytvoríme tabuľku čitateľ_novín,
kde jeden stĺpec bude odkazovať na tabuľku čitateľov a druhý na tabuľku
novín. V každom riadku tejto vyrovnávacej tabuľky teda bude identifikátor
čitateľa novín, ktorý bude vyjadrovať, že daný čitateľ číta dané
noviny. Jeden čitateľ môže mať v tabuľke viac záznamov (riadkov), ale žiadne
noviny sa nesmú pre toho istého čitateľa opakovať dvakrát - každý záznam
musí byť unikátny. Takto vytvorená tabuľka môže dať odpoveď kto číta
aké noviny, naopak kto je čitateľom tých ktorých novín.
Častým problémom SQL databáz je hlavne definovanie a práca s hierarchickými vzťahmi (t.j. vzťahmi nadriadenosti a podriadenosti). V týchto prípadoch majú záznamy často stromovú štruktúru a efektívne s nimi pracovať znamená používať rekurziu, ktorá je pre SQL cudzím javom. Napríklad ak chcete popísať rozsiahlu organizačnú štruktúru nejakej organizácie, musíte v rámci jednej tabuľky definovať vzťahy medzi záznamami v rámci tej istej tabuľky. To sa urobí tak, že napríklad vedľa stĺpca ktorý jednoznačne identifikuje riadky sa pridá ešte jeden ktorý udáva nadriadený záznam. V praxi to znamená definovať REFERENCES ktoré ukazujú do tej istej tabuľky (vid. spomenutý príklad - TABLE hier).
Metóda tvorby datového modelu
Ak chcete dosiahnúť optimálny návrh DB, je vhodné postupovať podľa presnej metódy. Postup je vhodné rozdeliť na tieto časti:
- zhromaždovanie dát a požiadavok od užívateľov a zadavateľov systému. Táto činnosť vyžaduje často veľa trpezlivosti, pretože ide o prácu s ľuďmi, ktorí o profesionálnom návrhu databáz nemajú ani šajn. Často je dobré myslieť aj za nich, nečakať len na to na čo sami prídu, ale im dávať otázky dopredu. Profesionálny návrhár už z povahy dát vie usúdiť aké možné informácie sa dajú z danej množiny dát získať.
- ďaľším krokom je definícia nezávislých entít
- definícia vzťahov a typov týchto vzťahov
- definícia závislých entít a vyhľadanie kandidátov na kľúčové atribúty.
Vyššie uvedený postup sa cyklicky opakuje tak dlho pokiaľ sa nepodarí vyriešiť všetky vzťahy. Po tejto fáze navrhu DB by už mala existovať dostatočne dobrá predstava o vzhľade výslednej databázy. Táto fáza návrhu je šete dosť obecná, takže pri vzťahu medzi entitami môžeme ešte pracovať aj so vzťahmi M:N, ktoré až neskôr transformujeme do "medzitabuliek".
V ďaľšej fáze sa formulujú a definujú jednotlivé atribúty a tabuľky sa normalizujú tak, aby sme dosiahli stupeň normalizácie 3NF (tretia normálna forma). Ide hlavne o finálne upresnenie primárnych kľúčov a vzťahov ostatných stĺpcov k nim.
Výsledkom tejto fázy vývoja by mal byť nejaký diagram (ERD alebo UML). Tento diagram vám poslúži pri tvorbe zložitejších SQL požiadaviek. Dobré je, aj keď sa to vždy nerobí vzťahy v diagramoch pomenovať.
Až vo finále by sme mali pristúpiť k optimalizácii dátových typov, a to väčšinou s prihliadnutím už k určitému typu SQL servera.
Obľúbenou témov mnohých debát je výber SQL servera. Výber by sa mal uskutočniť až na základe vymysleného dátového modelu, a to tak, aby sa mohol dátový model v SQL implementovať.
Väčšina používaných SQL serverov (Interbase, PostgreSQL, DB2, Sybase, Oracle, Informix) vám najpravdepodobnejšie poskytne dostatočné prostriedky na implementáciu ovyklých dátových modelov. Avšak napríklad MySQL v prípade cudzích kľúčov a referenčnej integrity dat asi nebude spĺňať základnú poučku o samostatnosti dátového modelu (? ... a bude do navrhu nutne zahrnout i nutnost implementovat niektoré veci vo vrstve nad touto DB - toto nateraz som nepochopil čo tým autor mienil).
Až v tejto chvíli má zmysel transformovať navrhnutú schému do SQL príkazov. V prípade ak používate nejaký CASE nástroj (t.j. nástroj pre automatizovaný návrh), môže ísť o dosť jednoduchú úlohu.
Popísaný postup rieši to, ako existujúce informácie transformovať do SQL schémy, ale nerieši to, ako sa neutopiť v záľahe informácií a ako ich analyzovať. V prípade skutočne rozsiahlych schém je vhodné sa rozhodnúť pre nejakú stratégiu ako sa s takou úlohou vysporiadať bez toho aby neutrpelo vaše duševné zdravie.
Existujú štyri základné stratégie:
- zhora dole
Zadanie sa postupne rozpitváva na menšie a menšie detaily. Analytik musí byť vybavený schopnosťou abstraktného myslenia a musí vedieť pri rozpitvať jednotlivé stupne a na nič nezabudnúť. - zdola nahoru
Ti sa riešia jednotlivosti na najnižšej úrovni a skladajú sa do väčších celkov. Výhodou je možnosť zadanie rozdeliť medzi viac členov týmu. Navýhodu je zase pri zostavovaní celku nevyhnutnosť častejších zmien, pretože niektoré veci "vyplavú na povrch" pri finálnom zostavovaní schémy. Na začiatku je možné, že budete plavať v mori dát, preto je vhodné ich rozdeliť medzi viacero pracovníkov. - zvnútra von
Podobne ako v predošlom prípade. najde sa nejaký zásadný a dôležitý bod a postupne sa dostávame k iným zásadným a dôležitým bodom. pekným prirovnaním je šírenie sa olejových škvŕn. Na začiatku niekoľko malých škvŕn sa neskor zväčší z zlejú sa do jednoh celku. - zmiešaná
V prevej fáze sa zadanie rodelí na viacero častí (kostrová schéma) a v druhej fáze sa jednotlivé časti analyzujú metódou zhora dole. Nakoniec sa vzniklé schémy integrujú do jednoho celku.
Kreslenie schém databáz.
Popísať niečo slovami môže byť velmi náročné, preto už od databázového praveku existujú spôsoby názorného zakreslenia databáz. V prípade väčších databáz by mal byť diagram práve tým prostriedkom s ktorým sa pracuje. Pokiaľ ste nútení vytvárať SQL žiadosti pre rozsiahlejšiu databázu, potom možnosť nahliadnúť do schémy je veľmi príjemná.
Súhrnne sa diagramy databáz prezentujú skratkou ERD (entity relationship diagram - diagram vzťahov entít /niekedy nazývaneé aj ERA - entity relationship and atributes/). Pretože ako to býva, nič nemôže byť jednoduché, aj pre toto existuje niekoľko systémov robiacich to isté (OMG, ORM, UML, IDEF1X, Crow's Foot, Bachman, Chen, James Martin) a treba povedať, že v rôznych programoch sa môžu použité značky mierne líšiť alebo kombinovať. Vzhľadom na to, že na kreslenie týchto diagramov najskôr budete používať nejaký vlastný program, nebudeme sa touto témou zaoberať. Žiaľ tie najlepšie programy na ERD a generovanie SQL príkazov pre tvorbu DB sú väčšinou len za nemalé peniaze.
ERD diagramy popisujú statickú štruktúru databázy. Pre popis toku dát a podobné veci slúžia napríklad niektoré podmnožiny UML (?).
Pôvodným typom ERD je Chenova metóda (Peter Chen 1976). Pre svoju názornosť sa väčšinou používajú v štúdijných materiáloch alebo dokumentoch ktoré popisujú nejaký jav a pod. tento štýl diagramu je dosť náročný na priestor, takže k popisu rozsiahlejších DB ani nie je dosť vhodný a väčšina schém, ktoré uvidíte, bude v niektorej z novejších a úspornejších metód grafickej prezentácie. Túto pôvodnú metódu ovláda napríklad program dia nebo tcm a rad iných (väčšinou komerčných) programov. Ukážky týchto metód napríklad nájdete na adrese [http://panoramix.univ-paris1.fr/CRINFO/dmrg/MEE/misop003/miso5.html] http://panoramix.univ-paris1.fr/CRINFO/dmrg/MEE/misop003/miso5.html.
Ďaľšou používanou je Crow's Foot metóda zobrazenia (je akceptovaná v Information Engineering Methodology (IEM) a potom ešte metóda IDEF1X. Tieto metódy používa aj český program XTG. Z jeho dokumentácie je nasledovná ukážka popisu:
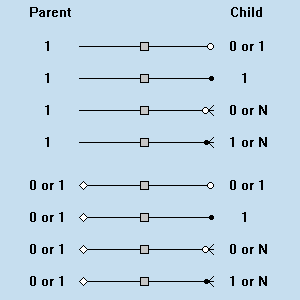
ERD je vhodné zakresliť horizontálne (zľava doprava), bez šikmých čiar. Jednotlivé spojnice kresliť dostatočne ďaleko od seba, aby nedošlo ku ich zámeme. Každý diagram by mal byť identifikovateľný, to znamená že má obsahovať nejaký popis.
[photos/xtg.png] 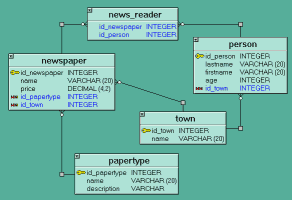
Ukažka je z programu XTG Data Modeller.
Odkazy o ERD:
[http://www.smartdraw.com/resources/centers/software/erd.htm] How to Draw Entity Relationship Diagrams (ERD)
[http://panoramix.univ-paris1.fr/CRINFO/dmrg/MEE/misop003/] The Entity-Relationship Diagram Technique
Software na ERD:
[http://orafaq.com/tools/] Co doporucuje Oracle
[http://www.karyopse.de/dia2sql/] Entity Relationship using Linux and Dia
[http://www.datanamic.com/dezign/index.html] DeZign for databases
[http://www.casestudio.com/csy/] CASE Studio 2 CZ
[http://www.xtg.cz/] XTG Data Modeller
[http://www.minq.se/products/dbvis/index.html] DbVisualizer (free, v jave)
[http://wwwhome.cs.utwente.nl/~tcm/] Toolkit for Conceptual Modeling (TCM)