Načo slúžia indexy
Databázové indexy slúžia na zrýchlenie prístupu k dátam a mali by sa používať pre všetky stĺpce, podľa ktorých sa vyhľadáva, triedi alebo podľa ktorých sa spájajú tabuľky.
Pri ukládaní dát do tabuliek nie sú záznamy obvyklie triedené a ukladajú sa zvyčajne za sebou tak ako sú vkladané. V momente keď chceme dáta z tabuľky opäť vybrať podľa nejakého kritéria, je potrebné prejsť všetkými záznamami a vybrať tie ktoré kritériám vyhovujú. Práve na to slúžia indexy, aby sme kôli niekoľkým záznamom nemuseli prehľadávať kompletný zoznam. Indexy sú zvyčajne zotriedené podľa znamych pravidiel, preto ak nájdeme prvý záznam, ktorý už evidentne nesplňuje podmienky, prehľadávanie môžeme zastaviť.
Indexy sa vytvárajú nad jedným, alebo niekoľkými stĺpcami tabuľky, každá tabuľka môže mať niekoľko indexov. Index vytvorený nad stĺpcom tabuľky umožňuje rýchly prístup k záznamu podľa hodnôt tohto stĺpca.
Organizácia dát v indexe umožňuje nielen priamy výber záznamu,s určitou
hodnotou, ale taktiež aj záznam v intervale hodnôt. Okrem toho sú prvky v
indexe previazané podľa poradia pri zoraďovaní (či sa už jedná o číselné
alebo reťazcové stĺpce), takže indexy umožňujú tiež rýchle zoradenie
tabuľky podľa stĺpcov, nad ktorými je index definovaný. Vďaka tomu umožňujú
aj rýchlý výber minima a maxima. Informáciu o počte hodnôt a počte
rôznych hodnôt (SQL funkcie
COUNT a COUNT
DISTINCT) databázy obvykle uchovávajú nezávisle od indexa v štatistikách
tabuľky, ktoré používajú taktiež napríklad pri hľadaní stratégie pre
vyhodnocovanie zložitejších požiadaviek na výber dát.
Indexy nad reťazcovými stĺpcami umožňujú taktiež rýchlejšie vyhľadávanie
pomocou operátorov LIKE, avšak len v
prípade, kedy je známy začiatok hľadaného výrazu - teda napríklad X
LIKE 'text%' využitie indexov dovoľuje,
ale X LIKE '%text%' nie.
Použitie indexov sa často zanedbáva a faktom je, že u malých tabuliek obahujúcich rádove desiatky záznamov je ich význam zanedbateľný. U väčších tabuliek naopak indexy výkon ovplyvňujú zásadne. Vzhľadom k tomu, že správa indexov stojí čas určitej réžie pri každom vkladaní a záznamu alebo jeho rušení, mali by sme sa vytvárania indexu vzdať utých tabuliek do ktorých sa údaje väčšinou vkladajú a len občas sa z nich údaje čítajú - napríklad log súbory.
Okrem bežných indexov možno tiež definovať unikátne indexy, ktoré do
tabuľky nedovolia vložiť viac záznamov s rovnakou hodnotou stĺpcov, nad
ktorými je index definovaný - s jedinou výnimkou tvorenou
hodnotou NULL . Táto informácia
môže poslúžiť databázovému servru taktiež k efektívnejšiemu
usporiadaniu dát. Špeciálnym typom indexu je primárny kľúč, ktorý
oznamuje stĺpce ktoré jednoznačne identifikujú ľubovolný záznam v tabuľke.
Definovanie primárneho kľúča by malo byť samozrejmosťou.
Po vytvorení indexu sa už oň nemusíme starať, databázový server sám
zaisťuje ich automatickú aktualizáciu a sám rozhoduje o tom, aké indexy využije
pri získavaní dát. Pokiaľ nás zaujíma, aké indexy srver použije, môžeme
v MySQL a u niekoľkých ďaľších servrov použiť príkaz EXPLAIN.
Príkazy pre prácu s indexom
K vytvoreniu indexu slúži v MySQL príkaz:
CREATE
[UNIQUE] INDEX nazov
ON tabuľka (stĺpec, ...)
Index sa taktiež vytvorí priamo pri vytvorení tabuľky:
CREATE TABLE
tabuľka (..., {INDEX|UNIQUE|PRIMARY
KEY} [názov]
(stĺpec, ...), ...)
Odstránenie indexu zaisťuje DROP INDEX
názov ON tabuľka,
s indexami sa dá pracovať i
pomocou príkazu ALTER TABLE.
Názov indexu nie je veľmi dôležitý a využijeme ho v podstate len pri prípadnom odstraňovaní indexu. Ak názov neuvedieme, vytvorí sa automaticky. U iných databázi slúžia pre prácu obdobné príkazy.
Server MySQL dovoľuje taktiež definíciu indexu iba nad začiatkom reťazca, čo šetrí miesto nevyhnutne potrebné pre uloženie indexu a používa sa v prípade, keď sa dáta v dlhom reťazcovom stĺpci líšia už svojim začiatkom. Miesto stlpec stačí v definícii indexu napísať stĺpec(X) , kde je X dĺžka začiatku reťazca, ktorý chceme pri vytváraní indexu využiť.
Indexy nad viacerími stĺpcami
Ak pri získavaní dát vykonávame hľadanie, triedenie, alebo kombináciu
oboch nad viacerími stĺpcami, je vhodné definovať index nad viacerími stĺpcami.
Je dobré si uvedomiť, že definovanie indexov nad viacerími stĺpcami je niečo
iné ako definovať viac indexov nad jedným stĺpcom. Ak totiž máme napr.
podmienku X=3 AND Y=4 a indexy (X) a
(Y), môže sa pre vyhľadanie odpovedajúcich riadkov použiť len
jeden index
(obvykle ten, ktorý množinu riadkov viac zredukuje) a riadky vyhovujúce druhej
časti podmienky sa musia dodatočne vyhľadať záznam po zázname. Ak je
však definovaný index (X, Y), môže sa použiť priame vyhľadanie
všetkých odpovedajúcich záznamov.
Z indexu nad viacerími stĺpcami môže databázový server pri čítaní
využiť taktiež ľubovolný začiatok, nemôže však použiť ľubovolnú
podmnožinu. Index (X,
Y) tak môže použit pri vyhľadávaní podľa stĺpca X,
ale už nie podľa stĺpca Y. Dáta pre stĺpec Y sú totiž
organizavané až v závislosti na hodnotách v stĺpci X.
Implementácia indexu databázami
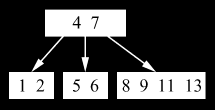 Indexy
sa obvykle implementujú pomocou B-stromu, čo je datová štruktúra, ktorá
umožňuje vkladanie, mazanie a vyhľadávanie prvku s amortizovanou časovou
zložitosťou O(log
N), kde N je počet prvkov v strome. Každý vrchol stromu obsahuje
nejmenej t-1 a nejviac 2t-1 prvkov, kde t je faktor stromu,
pre koreň stromu za určitých okolností stačí, aby bola splnená iba druhá
podmienka. Prvky sú vo vrchole usporiadané a z každého vrcholu vedie n(x)+1
ukazateľov na jeho synov, kde n(x) je počet prvkov vrcholu
x. Každý ukazateľ vľavo ukazuje iba na prvky s menšími než je daný
prvok, ukazateľ vpravo naopak na vrcholy s väčšími prvkami. Rýchlosť operácie
vyhľadávania zaručuje to, že všetky cesty z koreňa do listov musia
mať rovnakú dĺžku a že počet prvkov v každom vrchole je z oboch strán
omedzený. Okrem rýchlosti operácií majú B-stromy oproti iným datovým štruktúram
tiež tú výhodu, že pri všetkých operáciách potrebujú málo prístupov
na médium, na ktorom sú uložené (čo zvyčajne nie je Op.pamäť, ale disk).
Indexy
sa obvykle implementujú pomocou B-stromu, čo je datová štruktúra, ktorá
umožňuje vkladanie, mazanie a vyhľadávanie prvku s amortizovanou časovou
zložitosťou O(log
N), kde N je počet prvkov v strome. Každý vrchol stromu obsahuje
nejmenej t-1 a nejviac 2t-1 prvkov, kde t je faktor stromu,
pre koreň stromu za určitých okolností stačí, aby bola splnená iba druhá
podmienka. Prvky sú vo vrchole usporiadané a z každého vrcholu vedie n(x)+1
ukazateľov na jeho synov, kde n(x) je počet prvkov vrcholu
x. Každý ukazateľ vľavo ukazuje iba na prvky s menšími než je daný
prvok, ukazateľ vpravo naopak na vrcholy s väčšími prvkami. Rýchlosť operácie
vyhľadávania zaručuje to, že všetky cesty z koreňa do listov musia
mať rovnakú dĺžku a že počet prvkov v každom vrchole je z oboch strán
omedzený. Okrem rýchlosti operácií majú B-stromy oproti iným datovým štruktúram
tiež tú výhodu, že pri všetkých operáciách potrebujú málo prístupov
na médium, na ktorom sú uložené (čo zvyčajne nie je Op.pamäť, ale disk).
O B-stromoch sa dá viac dozvedieť napr. na adrese [http://www.bluerwhite.org/btree/] www.bluerwhite.org/btree/. V databázach sa pre indexy používa okrem B-stromov napr. taktiež hašovanie, ale len u niektorých databáz a len v niektorých prípadoch.
Príklad
Vytvoríme jednoduchú aplikáciu, v ktorej budú môcť registrovaní užívatelia vkladať príspevky do rôznych diskusných skupín. Užívatelia sa budú prihlasovať pomocou loginu, diskusné skupiny budeme vypisovať zoradené podľa názvu a príspevky v nich potom podľa dátumu vloženia. Na samostatnej stránke potom budeme vypisovať niekoľko najnovších príspevkov nezávisle od skupiny. Tabuľky zo správne vytvorenými indexami by v MySQL mohli vyzerať takto:
CREATE TABLE
uzivatelia (
id int
NOT NULL AUTO_INCREMENT,
login
varchar(32) NOT NULL,
jmeno
varchar(100) NOT NULL,
UNIQUE
(login),
PRIMARY
KEY (id)
);
CREATE TABLE
skupiny
(
id
int NOT NULL
AUTO_INCREMENT,
nazov
varchar(100) NOT NULL,
INDEX
(nazov),
PRIMARY KEY
(id)
);
CREATE TABLE
prispevky
(
id
int NOT NULL
AUTO_INCREMENT,
skupina
int NOT
NULL
REFERENCES skupiny(id),
uzivatel
int NOT NULL REFERENCES
uzivatelia(id),
nadpis
varchar(100) NOT NULL,
vytvorene
datetime NOT NULL,
prispevok
text NOT NULL,
INDEX
(skupina, vytvorene),
INDEX
(vytvorene),
PRIMARY KEY
(id)
);
Všetky
tabuľky majú automaticky generovaný primárny kľúč. V tabuľke
uzivatelia by ako primárny kľúč
mohol poslúžiť aj stĺpec login,
pre umožnenie jeho jednoduchej zmeny je však výhodnejšie definovať umelý
primárny kľúč a nad stĺpcom login
vytvoriť unikátny index. V tabuľke prispevky je definovaný
jednak index nad stĺpcom vytvoreno,
ktorý sa využije pri vypisovaní niekoľkých najnovších príspevkov nezávisle
od skupiny. Pre výpis v skupinách sa potom využije index
(skupina, vytvorene) - napr. v žiadosti:
SELECT
prispevky.*, uzivatelia.jmeno
FROM
prispevky
LEFT JOIN
uzivatelia ON prispevky.uzivatel =
uzivatelia.id
WHERE skupina = @skupina
ORDER BY
vytvorene DESC
Pokiaľ by sme užívateľovi chceli umožniť vypísať všetky jeho príspevky
zoradené podľa dátumu, bolo by vhodné ešte vytvoriť index (uzivatel,
vytvorene), inak však stĺpec uzivatel
nie je v indexoch potrebný - v nasej žiadosti je v okamžiku spojovania
tabuliek jeho hodnota už známa.
Záver
U aplikácie, ktorá pracujú s tabuľkami ktoré obsahujú len niekoľko desiatok riadkov, nie je použitie indexov až také nevyhnutné. Ale aj u takýchto tabuliek je dobrým zvykom vytvárať indexy súčasne s dátovou štruktúrou a sústrediť sa tak nielen na to, ako budú dáta v databáze uložené, ale taktiež na to, ako sa s týmito dátami bude pracovať. U tabuliek s väčším počtom riadkov je správna práca s indexami pre rýchlosť aplikácie zvyčajne rozhodujúca.