Prošli jsme výukou jazyka C až do konce. Přesto, že jsme jazyk zvládli, stále nám chybí něco, co ovšem není přímou součástí jazyka. Schopnost vytvářet a spravovat rozsáhlejší projekty1.
V čem je vlastně problém? C již známe. Celý projekt tedy můžeme napsat do jednoho souboru. A je to. Ano, tento přístup je jistě možný. Nejspíš ovšem jen teoreticky. Představme si program dlouhý deset, dvacet, nebo sto tisíc řádků. Naše orientace v tak dlouhém zdrojovém textu by byla velmi nesnadná. Navíc je málo provděpodobné, že by tak dlouhý kód vytvářel jediný člověk2. Pokud jich bude více, vznikl by problém se sdílením takového souboru. Teď vezměme v úvahu i specializaci. Nejen programátorů, ale i zdrojového kódu.
Podobné úvahy bychom mohli dále rozvíjet. Naštěstí nezačínáme na zelené louce. Programy v C psaly zástupy programátorů před námi. Teoretici posouvali hranici poznání. V C můžeme úspěšně pracovat modulárním způsobem. Projekt rozdělíme vhodným3 způsobem na menší části. Inspirací nám mohou být hlavičkové soubory.
Máme-li projekt rozdělen, musíme být schopni definovat závislosti jednotlivých jeho částí. Co se stane, když opravíme v jednom ze souborů hlavičku funkce. Musíme znovu přeložit celý projekt, nebo stačí přeložit jen jeho část. Povšimněme si, jakou výhodu nám rozdělení projektu může přinést. Nemusíme vždy překládat všechny části projektu. Stačí přeložit jen ty změněné, dále pak jen soubory, které změna ovlivní.
Pro usnadnění správy projektů se používá program make.
Program je řízen textovým souborem, definujícím vzájemné závislosti
souborů projektu, konfiguraci překladače, informace o adresářích.
Je zřejmé, že možnosti jazyka, popisujícího zmíněné závislosti
musí být poměrně značné. Myšlenka sama zcela zapadá do konstrukce
Unixu (v něm C vzniklo). Nepsat jeden rozsáhlý komplexní
program, ale více malých. make prostě čte řídící informace
a podle stavu, v němž se právě nachází, vyvolává pro
vykonání potřebných akcí odpovídající programy. Informace jim
předává jako argumenty. Výhodou je značná pružnost. A
rovněž jistá nezávislost na použitém překladači.
Teoreticky i na operačním systému.
Projekt umožňuje nezávislý překlad svých částí.
Nakonec tyto přeložené části spojíme ve výsledný spustitelný
tvar programu. Háček je v tom, že části sice můžeme překládat
nezávisle, ovšem musíme být schopni předávat z nich
informace, potřebné při překladu v částech jiných.
Definujme například ... . Ale raději opusťme teoretické úvahy.
Vždyť metologii návrhu a analýzy je věnováno mnoho rozsáhlých publikací.
Nebudeme se snažit jejich obsah shrnout v části malého
dodatku skripta. Ukažme si raději základní myšlenky na příkladu.
Projekt: Naším úkolem je umožnit převod vnitřního tvaru informací (výčtové hodnoty) na vnější (řetězce). Dále je naším úkolem odladit některé matematické funkce a umístit je odděleně. Tím umožníme jejich nezávislé použití4.
Po obecném zadání poznamenejme, že v praxi pochopitelně víme, co se od nás očekává. Zvolme si proto konkrétní funkce.
Náš projekt je evidentně ryze výukový. Je na první
pohled zřejmé rozdělení funkcí do souborů. Funkci, související
s prvním bodem, umístíme do jednoho souboru, funkce pokrývající
bod druhý do druhého souboru. Třetí soubor bude obsahovat funkci main().
Z něj budeme celý program řídit.
Protože ANSI C vyžaduje deklarace pro všechny použité
funkce, vytvoříme k prvnímu i druhému souboru deklarace těch funkcí,
které budeme chtít používat vně těchto souborů5. Schéma
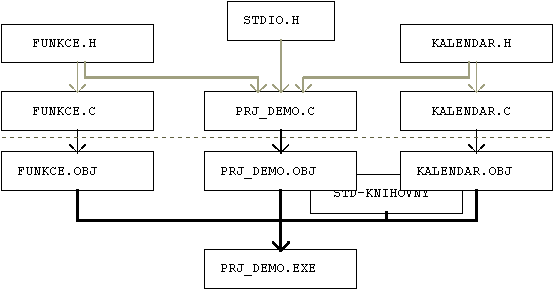
našeho projektu vidíme na obrázku.
Na obrázku vidíme tři základní soubory funkce.c, prj_demo.c
a kalendar.c a hlavičkové soubory kalendar.h
a funkce.h. Ty deklarují nejen funkce, ale v případě kalendar.h
definují i nové datové typy (viz výpis zdrojového textu dále).
Proto je začleňujeme jak do prj_demo.c, ale i do
"jejich" zdrojových souborů. Ve zdrojových souborech
jsou jen definice funkcí. Případně definice těch objektů (typů,
proměnných, funkcí, ... ), které nechceme dát vně k
dispozici. Do prj_demo.c musíme ještě připojit stdio.h,
neboť obsahuje i vstupní a výstupní operace.
Obrázek obsahuje mnohem více informací, než jsme dosud popsali. Vodorovná přerušovaná čára odděluje textové informace, které do projektu vstupují, od jejich překladu.
Každý ze zdrojových textů *.c může být
samostatně přeložen. Postačují mu informace z hlavičkových souborů
(viz obrázek). Jejich překladem jsou *.obj soubory6.
Spojením *.obj souborů a připojením kódu ze
standardních knihoven (v obrázku jsou označeny symbolicky),
vytvoříme spustitelný tvar programu. Jeho začátek (vstupní
bod) je jednoznačně určen. Funkce main() musí být
v celém projektu právě jediná. Ve fázi spojování se mohou
odhalit chyby při návrhu projektu. Pokud například definujeme
funkci nebo deklarujeme proměnnou na více místech. To je častá
chyba začátečníků - definují funkci v hlavičkovém
souboru. Díky jeho začlenění do více modulů získají
nechtěně více definic téže funkce. Jak se pak má zachovat
spojovací program, když narazí na týž identifikátor ve více
modulech? Jednoznačně, oznámí chybu a ukončí svou činnost. Všechny
moduly jsou si z tohoto pohledu rovnocenné.
Vysvětlili jsme si závislosti v ukázkovém projektu. Podívejme
se nyní na (mírně zkrácenou) ukázku make
souboru, vytvořeného pro tento projekt. Jeho tvorba proběhla
automaticky programem prj2mak z balíku podpůrných
programů BC31.
.AUTODEPEND .PATH.obj = C:\BIN # *Translator Definitions* CC = bcc +PRJ_DEMO.CFG TASM = TASM TLIB = tlib TLINK = tlink LIBPATH = C:\BC\LIB INCLUDEPATH = C:\BC\INCLUDE # *Implicit Rules* .c.obj: $(CC) -c {$< } .cpp.obj: $(CC) -c {$< } # *List Macros* EXE_dependencies = \ funkce.obj \ prj_demo.obj \ kalendar.obj # *Explicit Rules* c:\bin\prj_demo.exe: prj_demo.cfg $(EXE_dependencies) $(TLINK) /v/x/c/P-/L$(LIBPATH) @&&| c0s.obj+ c:\bin\funkce.obj+ c:\bin\prj_demo.obj+ c:\bin\kalendar.obj c:\bin\prj_demo # no map file emu.lib+ maths.lib+ cs.lib | # *Individual File Dependencies* funkce.obj: prj_demo.cfg funkce.c prj_demo.obj: prj_demo.cfg prj_demo.c kalendar.obj: prj_demo.cfg kalendar.c # *Compiler Configuration File* prj_demo.cfg:prj_demo.makcopy &&| ... zkráceno -nC:\BIN -I$(INCLUDEPATH) -L$(LIBPATH) -P-.C | prj_demo.cfg
Po podrobném rozboru projektu se již podíváme na jeho
zdrojové texty. Začneme hlavním z nich. Obsahuje funkci main()
a volá ostatní funkce definované vně něj. Najdeme v něm dva
cykly, které by měly zajistit správné načtení vstupních
hodnot. Ty jsou pak převedeny či přepočteny a zobrazeny. Odpovídající
volání funkcí jsou umístěna přímo ve funkci printf().
Jejich výsledky tedy jsou použity jako argumenty formátovaného
výstupu.
/******************************/ /* souborPRJ_DEMO.C*/ /* ukazka maleho projektu */ /* pouziva funkce ze souboru: */ /* FUNKCE.C, KALENDAR.C */ /******************************/ #include <stdio.h> #include "funkce.h" #include "kalendar.h" int main(void) { int i = -1; tDen eden; do { printf("\nZadej den v tydnu jako cislo < 0, 6> :"); scanf("%d", &i); } while (i < 0 || i > 6); eden = (tDen) i; printf("\nZadal jsi: %s (anglicky: %s)\n", eden_sden(eden, eCZ), eden_sden(eden, eBE)); do { printf("\nZadej cele cislo do 20:"); scanf("%d", &i); } while (i < 0 || i > 20); printf("\n%d! = %0.0lf\t fib(%d) = %0.0ld\n", i, fact(i), i, fib(i)); return 0; } /* int main(void) */
Soubor kalendar.c definuje funkci eden_sden().
Zajímavá je definice statického dvourozměrného pole
řetězců v těle této funkce. Touto konstrukcí vytváříme
rozhraní pro pole sdny. Pole pak není na globální úrovni
viditelné, tedy není ani dostupné. Je odstíněno definovanými
službami, které zajišťuje právě funkce eden_sden().
/******************************/ /* souborKALENDAR.C*/ /* vyzaduje soubor KALENDAR.H */ /* definuje: */ /* - eden_sden() */ /******************************/ #include "kalendar.h" const char *eden_sden(tDen d, tLang l) /********************************************************/ /* prevede vyctovy den v tydnu na odpovidajici retezec */ /* ve zvolenem jazyce */ /********************************************************/ { static char *sdny[eBE+1][eNE+1] = {{"pondeli", "utery", "streda", "ctvrtek", "patek", "sobota", "nedele"}, {"Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"}}; return sdny[l][d]; } /* const char *eden_sden(tDen d, tLang l) */
Hlavičkový soubor kalendar.h obsahuje deklaraci
funkce eden_sden(). Jsou v něm definovány i dva výčtové
typy a řada výčtových konstant, náležejících k těmto
typům.
/************************************/ /* souborKALENDAR.H*/ /* hlavickovy soubor pro KALENDAR.C */ /* deklaruje a definuje: */ /* - eden_sden() */ /* - tDen, tLang */ /************************************/ typedef enum {ePO, eUT, eST, eCT, ePA, eSO, eNE} tDen; /****************************************************/ /* vyctovy typ pro den v tydnu */ /* PONDELI..NEDELE -> ePO..eNE (0..6) */ /****************************************************/ typedef enum {eCZ, eBE} tLang; /****************************/ /* vyctovy typ pro jazyk: */ /* CZ - cestina */ /* BE - British English */ /****************************/ const char *eden_sden(tDen d, tLang l); /********************************************************/ /* prevede vyctovy den v tydnu na odpovidajici retezec */ /* ve zvolenem jazyce */ /********************************************************/
Soubor funkce.c definuje funkce pro výpočet
faktoriálu a Fibonacciho posloupnosti. První z funkcí je
založena na iteraci. K tomu má cyklus for. Druhá
funkce je postavena na eleganci rekurse. Její jednoduchost je
ovšem draze vykoupena výrazně nižší výpočetní rychlostí
a vysokými nároky na velikost zásobníku. Z tohoto důvodu je
ve funkci main() omezen vstup na hodnoty do dvaceti.
/****************************/ /* souborFUNKCE.C*/ /* vyzaduje soubor FUNKCE.H */ /* definuje funkce: */ /* - fact() */ /* - fib() */ /****************************/ #include "funkce.h" double fact(int n) /***********************/ /* vypocte n faktorial */ /* pro n < 0 vrati -1 */ /***********************/ { double f = 1.0L; for ( ; n > 0; n--) f *= n; return f; } /* double fact(int n) */ long fib(long n) /******************************/ /* vrati hodnotu n-teho clenu */ /* Fibbonaciho posloupnosti */ /******************************/ { if (n == 1) return 1; else if (n == 2) return 2; else return fib(n - 1) + fib(n - 2); } /* long fib(long n) */
Poslední soubor projektu, funkce.h, obsahuje
hlavičky (deklarace) funkcí fact() a fib(). Připomeňme
si, že deklarace funkcí neobsahují tělo funkce. Mají však
popsány argumenty a jejich typy, stejně jako návratový typ.
Jsou ukončeny středníkem7.
/****************************/ /* souborFUNKCE.H*/ /* deklaruje funkce: */ /* - fact() */ /* - fib() */ /****************************/ double fact(int n); /***********************/ /* vypocte n faktorial */ /* pro n < 0 vrati -1 */ /***********************/ long fib(long n); /******************************/ /* vrati hodnotu n-teho clenu */ /* Fibbonaciho posloupnosti */ /******************************/
Vysvětlivky:
1 Pravdou
je, že tuto schopnost získáme teprve tehdy, když nějaký
projekt úspěšně ukončíme. A raději ne hned ten první.
2 V reálném
projektu je významný i časový faktor. Kolik kódu je schopen
jedinec zvládnout?
3 Tím
jsme si situaci pěkně zjednodušili. Otázkou zůstává, co je
to vhodný způsob. Pro začátek můžeme například oddělit
uživatelské rozhraní od zbylého kódu. Výkonnou část
programu rozdělíme do souborů podle příbuzných skupin funkcí.
4 Dokonce
po jejich přeložení i bez nutnosti následného použití
zdrojového textu.
5 V našem
případě budeme předávat informace o všech objektech. Tímto
způsobem se ovšem můžeme obecně chovat modulárně. Ze zdrojového
souboru zveřejníme v hlavičkovém souboru pouze informace,
které chceme dovolit exportovat.
6 Nebudeme
popisovat detailně více OS. Pro názornost nám postačí popis
v prostředí MS-DOSu.
7 Pokud na
středník zapomeneme, díky začlenění hlavičkového souboru
do jiných zdrojových textů se syntaktická chyba
pravděpodobně projeví na místě, kde ji zpravidla nečekáme.
V jazyce C prostě musíme být pozorní.
| Název: | Programování v jazyce C |
| Autor: | Petr Šaloun |
| Do HTML převedl: | Kristian Wiglasz |
| Poslední úprava: | 20.11.1996 |